Connexion d’une IA à une base de connaissance
Et si votre IA pouvait vraiment comprendre votre entreprise ?
Cet agent RAG (Retrieval-Augmented Generation) combine la puissance de l’IA et la précision de vos propres données pour créer un assistant capable de répondre de façon pertinente, documentée et contextualisée.
Grâce à une intégration fluide entre n8n, OpenAI et Supabase, ce système construit une IA qui ne se contente plus d’improviser : elle analyse vos fichiers, en extrait la connaissance, puis l’utilise pour fournir des réponses exactes et vérifiables.
Chaque interaction devient plus intelligente au fil du temps, grâce à une mémoire conversationnelle et une base de données vectorielle qui font le lien entre vos sources et les requêtes des utilisateurs.
Un outil pensé pour renforcer la fiabilité, accélérer l’accès à l’information et offrir une véritable intelligence augmentée au service de votre activité.
Fonctionnement du workflow
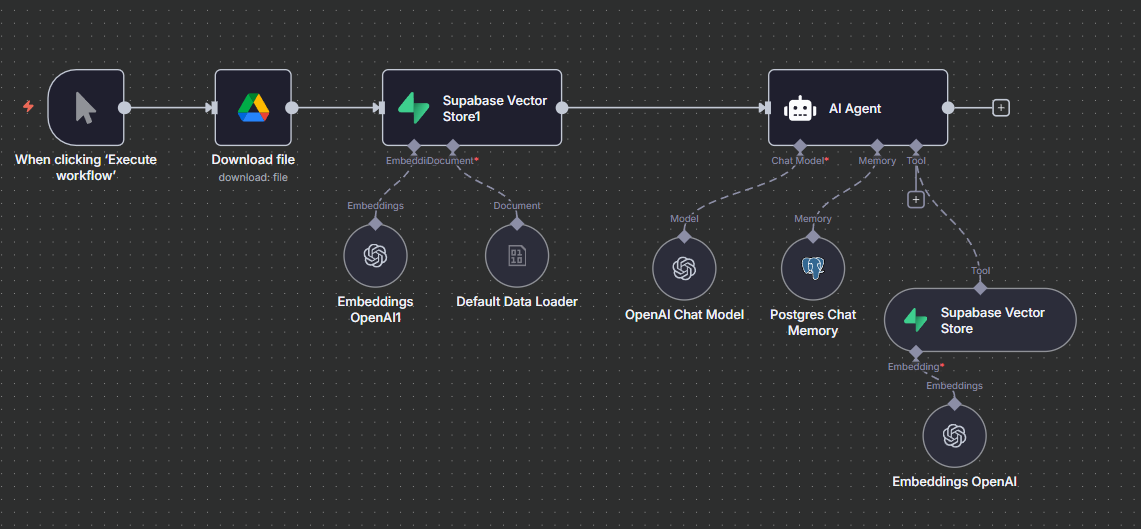
Download file : récupération du document source (ex. depuis Drive).
Default Data Loader → OpenAI Embeddings → Supabase Vector Store :
Le document est découpé, converti en vecteurs (embeddings) puis stocké dans Supabase pour la recherche sémantique.
OpenAI Chat Model : moteur de dialogue qui formulera la réponse.
Postgres Chat Memory : conservation du contexte et de l’historique des échanges.
Supabase Vector Store (tool) + Embeddings : à chaque question, l’agent interroge la base vectorielle, récupère les passages pertinents et les joint au prompt.
Réponse RAG : le modèle génère une réponse ancrée dans les extraits retrouvés, éventuellement avec références/citations.
Résultats
Moins d’hallucinations : réponses fondées sur des passages retrouvés dans vos sources.
Recherche en langage naturel dans vos fichiers et notes internes.
Mémoire de conversation (Postgres) pour conserver le fil et le contexte.
Mise à jour simple : il suffit d’ajouter/actualiser un document pour enrichir le savoir.
Technologies utilisées
Ce système s’appuie sur trois piliers :
n8n : le moteur d’automatisation qui orchestre l’ensemble du flux.
OpenAI : le modèle de langage qui comprend les questions et rédige les réponses.
Supabase : la base de données qui stocke les informations sous forme vectorielle pour permettre la recherche sémantique.
Cas d’usage
Ce type d’automatisation peut s’appliquer à de nombreux contextes :
Support interne : permettre aux équipes de poser des questions sur les procédures, guides ou politiques internes.
Documentation produit : interroger une base de fiches techniques ou de manuels utilisateurs.
Base de connaissances clients : fournir des réponses précises issues de vos articles d’aide.
Évolutions possibles
Ce système peut évoluer sans refaire tout le workflow :
Ajouter d’autres sources de données (Notion, Confluence, Drive, Base SQL…).
Connecter d’autres modèles d’IA (Anthropic, Mistral, Gemini…).
Mettre en place une interface web ou chatbot pour interagir directement.
Automatiser la mise à jour de la base vectorielle dès qu’un nouveau fichier est ajouté.
 using WordPress and
using WordPress and